
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- BOJ
- Codeup
- Java11
- programmers
- 백준
- 기초
- JAVA 11
- 개념
- Python
- 응용
- Python 3
- 공공데이터
- 기본
- GROUP BY 절
- 기초100제
- level1
- java
- Codeforces Round #802 (Div. 2)
- 명품 자바 프로그래밍
- SELECT 절
- 헤드퍼스트 디자인패턴
- 코딩테스트
- 자바
- 파이썬
- baekjoon
- 단계별로 풀어보기
- HAVING 절
- 이론
- pypy3
- SQLD / SQLP
Archives
- Today
- Total
Development Project
[ 2021 NIPA AI - 기본 ] 3. 공공데이터를 활용한 파이썬 데이터분석 프로젝트 - 1. 코로나 데이터 분석하기 본문
AI/Edu
[ 2021 NIPA AI - 기본 ] 3. 공공데이터를 활용한 파이썬 데이터분석 프로젝트 - 1. 코로나 데이터 분석하기
나를 위한 시간 2021. 12. 16. 12:52
데이터 출처 : https://www.data.go.kr/tcs/dss/selectFileDataDetailView.do?publicDataPk=15063273
서울특별시_코로나19 확진자 현황_20210422
서울특별시 코로나19 자치구별 일자별 확진자 현황에 대한 데이터로 연번, 확진일, 지역, 여행력, 접촉력, 등록일 등의 항목을 제공합니다.
www.data.go.kr
[Project 1] 코로나 데이터 분석
- 데이터 읽기
- 데이터 불러오기
- import
-
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
-
- 불러오기 [ read_csv("경로") ]
-
corona_all = pd.read_csv("./data/서울시 코로나19 확진자 현황.csv")
-
- 정보 출력 [ .head() / .info() ]
-
#상위 5개 데이터를 출력 corona_all.head()
-
# datafrmae 정보를 요약하여 출력 corona_all.info()
-
- import
- 데이터 불러오기
- 데이터 정제
- 비어있는 컬럼 지우기
- 컬럼 삭제 [ drop(columns = [ '컬럼명' ]) ]
-
corona_del_col = corona_all.drop(columns = ['국적', '환자정보', '조치사항'])
-
- 컬럼 삭제 [ drop(columns = [ '컬럼명' ]) ]
- 비어있는 컬럼 지우기
- 데이터 시각화
- 확진일 데이터 전처리하기
-
corona_del_col['확진일']
-
# => 월별, 일별 분석을위해 month, day 데이터로 나누기 month = [] day = [] # "월.일" 형식인 확진일을 구분자 '.'으로 구분 for data in corona_del_col['확진일']: month.append(data.split('.')[0]) day.append(data.split('.')[1]) # corona_del_col 테이블에 month, day 컬럼 생성 및 값 초기화 corona_del_col['month'] = month corona_del_col['day'] = day corona_del_col.head()
-
- 월별 확진자 수 출력
- seaborn의 countplot 함수로 출력 [ sns.countplot(x= , data= , order= ) ]
-
# 그래프에서 x축의 순서를 정리하기 위하여 order list를 생성 order = [] for i in range(1, 11): order.append(str(i)) # 그래프의 사이즈를 조절 plt.figure(figsize = (10, 5)) # seaborn의 countplot 함수를 사용하여 출력 sns.set(style = "darkgrid") ax = sns.countplot(x = "month", data = corona_del_col, palette = "Set2", order = order)
-
- series의 plot 함수로 출력
- [ .value_counts(subset = None, normalize = False, sort = True, ascending = False) ]
- subset
- 특정 조합의 개수를 셀 필요가 있을 경우 사용자가 원하는 조합의 열(또는 행)의 레이블을 입력받음
- normalize [ 기본값 : False ]
- 개수가 아니라 개수의 비율을 반환할지 여부를 결정
- sort [ 기본값 : True ]
- 결과를 정렬할지 여부를 결정
- ascending [ 기본값 : False ]
- 오름차순으로 정렬할지 여부를 결정
- subset
- [ .plot(kind= ) ]
-
corona_del_col['month'].value_counts().plot(kind = 'bar')
-
- [ .value_counts(subset = None, normalize = False, sort = True, ascending = False) ]
- 8월달 일별 확진자 수 출력
-
order2 = [] for i in range(1, 32): order2.append(str(i)) plt.figure(figsize=(20,10)) sns.set(style="darkgrid") ax = sns.countplot(x = "day", data = corona_del_col[corona_del_col['month'] == 8], palette = "rocket_r", order = order2)
-
- seaborn의 countplot 함수로 출력 [ sns.countplot(x= , data= , order= ) ]
- 지역별 확진자 수 출력
-
corona_del_col['지역']
- => '__구' 형태의 문자열 데이터로 저장되어있음
-
import matplotlib.font_manager as fm font_dirs = ['/usr/share/fonts/truetype/nanum', ] font_files = fm.findSystemFonts(fontpaths=font_dirs) for font_file in font_files: fm.fontManager.addfont(font_file) plt.figure(figsize=(10, 20)) sns.set(font='NanumBarunGothic", rc = {"axes.unicode_minus":False}, style='darkgrid') ax = sns.countplot(x = '지역', data = corona_del_col, palette = "Set2")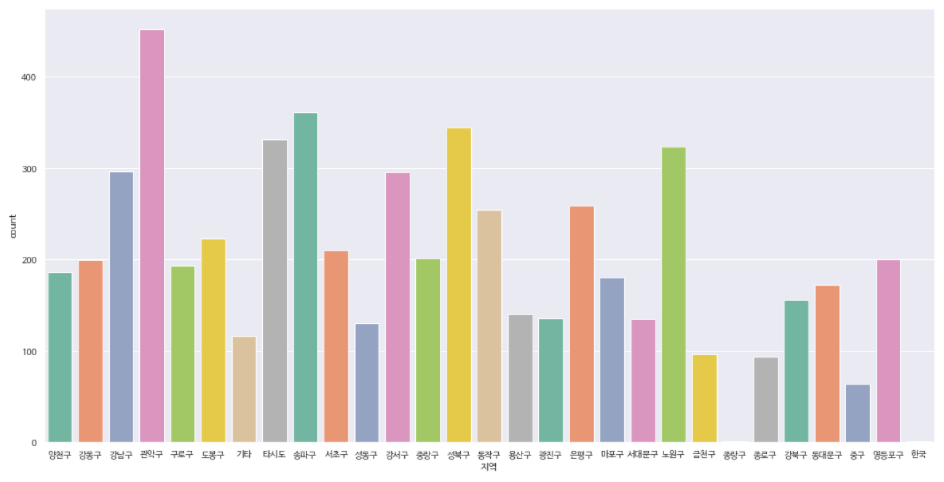
- => 잘못된 데이터가 존재 : '종랑구' (실제 중랑구), '한국' 데이터
-
# '종랑구'를 '중랑구'로, '한국'을 '기타' 컬럼으로 대체 corona_out_region = corona_del_col.replace({'종랑구':'중랑구', '한국':'기타'}) plt.figure(figsize=(20,10)) sns.set(font="NanumBarunGothic", rc={"axes.unicode_minus":False}, style="darkgrid") ax = sns.countplot(x="지역", data=corona_out_region, palette="Set2")
-
- 8월달 지역별 확진자 수 출력
-
# 8월 데이터만 출력 corona_out_region[corona_del_col['month'] == '8']
-
plt.figure(figsize=(20,10)) sns.set(font = "NanumBarunGothic", rc = {"axes.unicode_minus":False}, style = 'darkgrid') ax = sns.countlot(x = "지역", data=corona_out_region[corona_del_col['month'] == '8'], palette = 'Set2')
- ㅁ
-
- 월별 관악구 확진자 수 출력
-
corona_out_region['month'][corona_out_region['지역'] == '관악구'] plt.figure(figsize=(10,5)) sns.set(style='darkgrid') ax = sns.countplot(x="month", data=corona_out_region[corona_out_region['지역'] == '관악구'], palette='Set2', order = order)
-
- 서울 지역에서 확진자를 지도에 출력
- => 지역마다 지도에 정보를 출력하기 위해서는 각 지역의 좌표정보가 필요함
데이터 출처 : https://data.seoul.go.kr/dataList/OA-11677/S/1/datasetView.do
-
CRS = pd.read_csv("./data/서울시 행정구역 시군구 정보 (좌표계_ WGS1984).csv")
-
CRS[CRS['시군구명_한글'] == '중구']
-
import folium map_osm = folium.Map(location=[37.529622, 126.984307], zoom_start=11)
-
corona_seoul = corona_out_region.drop(corona_out_region[corona_out_region['지역'] == '타시도'].index) corona_seoul = corona_seoul.drop(corona_out_region[corona_out_region['지역'] == '기타'].index) # 서울 중구를 가운데 좌표로 잡아 지도를 출력 map_osm = folium.Map(location=[37.557945, 126.99419], zoom_start=11) # 지역 정보를 set함수를 이용해 25개의 고유의 지역을 뽑아냄 for region in set(corona_seoul['지역']): count = len(corona_seoul[corona_seoul['지역'] == region]) CRS_region = CRS[CRS['시군구명_한글'] == region] maker = folium.CircleMarker([CRS_region['위도'], CRS_region['경도']], # 위치 radius = count/10+10, # 범위 color = '#3186cc', # 선 색상 fill_color = '#3186cc', #면 색상 popup = ' '.join(region, str(count), '명'))) #팝업 설정 maker.add_to(map_osm)
- => 지역마다 지도에 정보를 출력하기 위해서는 각 지역의 좌표정보가 필요함
- 확진일 데이터 전처리하기
'AI > Edu' 카테고리의 다른 글
| [ 2021 NIPA AI - 기본 ] 3. 공공데이터를 활용한 파이썬 데이터분석 프로젝트 - 3. 자동차 리콜 현황 데이터를 활용한 데이터 분석 (0) | 2021.12.16 |
|---|---|
| [ 2021 NIPA AI - 기본 ] 3. 공공데이터를 활용한 파이썬 데이터분석 프로젝트 - 2. 지하철 승하차 인원 정보를 활용한 역별 혼잡도 분석 (0) | 2021.12.16 |
| [ 2021 NIPA AI - 응용 ] 2. 딥러닝 시작하기 (01~05) + α (0) | 2021.12.13 |
| [ 2021 NIPA AI - 응용 ] 1. 머신러닝 시작하기 (01~05) + α (0) | 2021.12.11 |
| [ 2021 NIPA AI - 기본 ] 2. 데이터 분석을 위한 라이브러리 (01~05) + α (0) | 2021.10.22 |
'AI/Edu' Related Articles
more




Comments